今回できたこと:東証株日報PDFからCSVへの書き出し、部分的にできた。
東証株日報(PDF)をDL、PDFMinerをつかってテキスト・ファイルとして保管したのをテキスト・エディタで見たら、ずいぶん不要部分がありました。それを削除し、銘柄ごとに1行になるようリスト化し、CSVでファイル書きだし(保管)できました。

DLしたPDFから作業が簡単そうな「単頁」を抜き出し、それを使い結果的にCSVまでできました。それをExcelで読み込んだのが上の画像(部分)です。
PDFMiner解析の結果、異なるところにテキスト・データが…。
テキストファイルで、PDF上で見たのと異なる位置にデータが現れるという事象がありました。多くは、一項目が二行で表示されているうちの第二行目が思わぬ位置に出現し、削除に手間取りました。具体的には、下の図です。
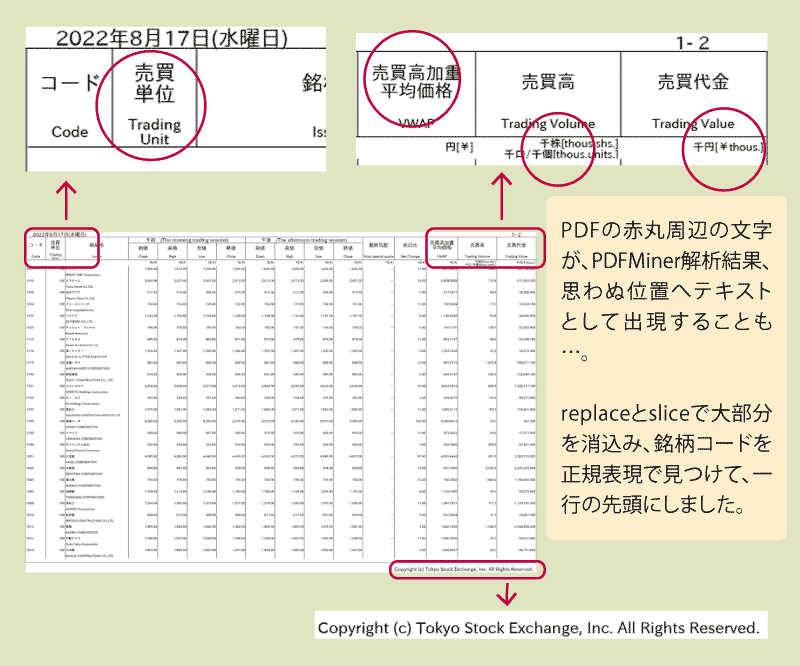
課題:複雑なページもある東証株日報PDF
東証株日報の先頭には、タイトルなどがあります。市場区分、業種名なども次々と現れます。これらをPDFMinerで処理したとき思わぬ位置にテキストが出現するのではないかと思っています。
また、単頁の処理がなんとか前進したからと言って、複数頁がうまくいくとは限りません。先はまだ長いと思います。ひとまずの途中経過でした。